INFO DI BASE
CONVIVENZA SISTEMA OPERATIVO EPROGRAMMI
- Un problema comune è riuscire a far convivere il sistema operativo (che gestisce le funzioni base del computer) e i programmi utente (applicazioni e software) nella stessa memoria, che è da vedere come un array di byte.
- Si usano diverse configurazioni per far funzionare tutto insieme. Questi sono tre schemi di organizzazione della memoria:
- ROM = contenuto + protetto, affidabile e veloce all’accensione ma lento agli aggiornamenti e poco flessibile
- RAM = contenuto + veloce agli aggiornamenti (pk avvengono nella RAM) e + flessibile ma dalla memoria limitata
- In RAM sia sistema operativo sia i programmi utente
- Caratteristiche:
- Questo approccio è comune nei computer general-purpose, come PC o laptop, dove il sistema operativo viene caricato nella RAM all'avvio.
- Vantaggio: Il sistema operativo può essere aggiornato facilmente poiché sta nella RAM.
- Svantaggio: riduce lo spazio disponibile per i programmi utente.
- Sistema operativo in ROM
- ROM (Read-Only Memory) → memorizza il codice NON MODIFICABILE di un programma, che di solito esegue operazioni fondamentali per il corretto funzionamento del programma/dispositivo
- I programmi utente hanno più spazio in RAM
- Applicazione tipica:
- Utilizzato in sistemi embedded semplici che richiedono un funzionamento affidabile e costante (specializzati nell’esecuzione di compiti specifici e ripetitivi)
- Esempio: Vecchi telefoni cellulari, microcontrollori, dispositivi IoT di basso costo.
- Affidabilità e avvio rapido, poiché il sistema operativo è sempre disponibile nella ROM.
- Mancanza di flessibilità, poiché gli aggiornamenti sono difficili.
- sistema operativo in RAM
- driver in ROM (quindi lo separo dal sistema operativo)
- device driver: programmi che consentono al sistema operativo di comunicare con l’hardware
- ALLOCAZIONE DINAMICA: i programmi utente vengono caricati in RAM quando necessario (in tanto stanno su disco)
- Applicazione tipica:
- Sistemi industriali complessi e macchinari automatizzati, dove le funzionalità sono limitate e specifiche (ad esempio, catene di montaggio).
- Esempio: Robotica industriale, controllori logici programmabili (PLC).
- Caratteristiche:
- I driver in ROM garantiscono una comunicazione affidabile con l'hardware, pk la ROM è generalmente più sicura
- flessibilità nella gestione dei programmi
- aggiornamenti rapidi del sistema operativo
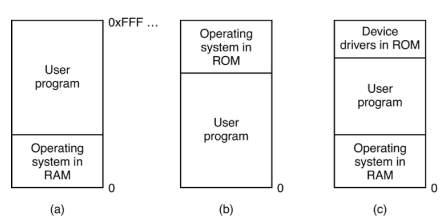
Caso (a):
RAM
Caso (b):
ROM
Caso (c):
ROM
RAM
SWAPPING COS’è
per ottimizzare la memoria
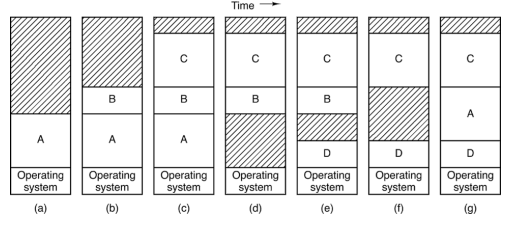
- Lo swapping è una tecnica che permette di spostare i processi in blocco da RAM a disco in una zona chiamata area swap, in modo che del processo in memoria rimanga solo il Process Control Block contenente le informazioni per il recupero del processo
- Quando un processo è in stato di bloccato (ad esempio, in attesa di I/O), può essere temporaneamente "swappato" su disco per liberare spazio in RAM.
PROBLEMINI
PROBLEMA = DESINCORNIZZAZIONE TRA INDIRIZZO PROCESSO E INDIRIZZO RAM
PREMESSA
Sia le istruzioni del programma sia gli indirizzi di memoria del computer sono numerati sequenzialmente a partire da 0.
- La numerazione delle istruzioni facilita il controllo del flusso di esecuzione da parte del Program Counter (PC), che si trova all’interno della CPU.
- La numerazione della memoria consente di localizzare le informazioni allocate o da allocare.
SPIGAZIONE PROBLEMA
- quando si caricano più programmi (considerando che la memoria è rappresentata come un array numerato di byte), solo il primo programma funziona correttamente. Questo accade perché i suoi indirizzi di memoria coincidono con quelli fisici della RAM.
- i programmi successivi, hanno indirizzi non sincronizzati con quelli della RAM, poiché i loro indirizzi interni ripartono da zero, mentre la memoria fisica della RAM continua da dove il primo programma è stato caricato. Di conseguenza, le istruzioni dei programmi successivi puntano a posizioni errate, causando inconsistenze e comportamenti imprevedibili.
ESEMPIO: Immagina un’istruzione di salto (jump) dalla posizione 0 alla posizione 24. Ma si tratta del secondo processo ed il computer l’ha inserito dalla posizione 75 in avanti, la CPU quindi torna indietro alla riga 24 del primo processo facendo casino pk intanto esce dallo spazio di indirizzamento del processo corrente
SOLUZIONE = ASTRAZIONE DI MEMORIA
- L’astrazione della memoria è un sistema che isola e gestisce gli indirizzi di memoria di ciascun programma, permettendo a ogni programma di operare come se fosse l’unico in esecuzione, anche quando in realtà ne sono caricati molti.
SOLUZIONE = ASTRAZIONE
PROCESSO DI ASTRAZIONE DELLA MEMORIA
Definisco la dimensione dello spazio reso disponibile al processo, in modo da dividere la memoria in n segmenti:
Caratteristiche della memoria segmentata
- ogni segmento è uno spazio dedicato ad un processo
- Memoria suddivisa in segmenti di dimensione variabile in base alle necessità.
- registro base = indirizzo iniziale della RAM per il processo
- registro limite= indirizzo finale della RAM per il processo
- Contenuto specifico per segmento: I segmenti possono essere dedicati a tipi specifici di dati (es. codice, dati, stack), rendendo più semplice liberarli quando non servono più.
In questo modo se il processo dovesse puntare ad una qualsiasi istruzione indetta da una JUMP, durante la sua esecuzione
- somma l’istruzione del processo con l’offset = registro base
- il processore verifica che il riferimento sia sotto
- se accade, solleva una trap di segmentation fault
PROBLEMA + SOLUZIONE = GESTIRE L’ALLOCAZIONE DINAMICA P.1 (struttura processo), p.2 qui
il sistema nn conosce a priori la dimensione precisa da allocare, pk durante l’esecuzione il processo può crescere (allocazione dinamica) questo è gestito in 2 modi possibili
SOLUZIONE
Assegno un segmento appena un po’ più grande per ogni processo:
In un sistema Unix, ogni processo ha tre segmenti di memoria principali, ognuno con una funzione specifica
- Segmento di testo: contiene il codice eseguibile del processo (text segment)
- È una zona di memoria di dimensione fissa: non può crescere né ridursi, perché rappresenta il codice eseguibile che è stabile e non necessita di modifiche durante l'esecuzione.
- Segmento dati (heap): contiene variabili del programma (data segment)
- cresce verso indirizzi di memoria più alti
- usato per memorizzare i dati che devono essere allocati dinamicamente, cioè quando il programma è in esecuzione
- Segmento stack: contiene le chiamate di funzione e le variabili locali (stack segment)
- Cresce verso indirizzi di memoria più bassi
IN CASO DI COLLISIONE
Se lo stack e l'heap si incontrano il sistema operativo rileva il problema e genera una trap di segmentation fault per eliminare il processo → come nel caso di una jump fuori dal processo correntemente in esecuzione (qui)
PROBLEMA NELL’ALLOCAZIONE DI PROCESSI (indipendentemente dall’algoritmo)
FRAMMENTAZIONE ESTERNA (cos’è)
Ogni processo occupa un segmento di grandezza variabile e ciò causa una scenario tipico di rallentamento della CPU = frammentazione esterna
- nel tentativo di caricare programmi nei negli spazi disponibili, se alla fine della RAM nn c’è spazio sufficiente per caricare il processo seguente, allora esso dovrà aspettare che i processi già in RAM lasciano lo spazio che spesso nn è preciso ma in eccesso, causando una progressiva frammentazione della memoria RAM che alterna spazi liberi(buchi) e spazi occupati
SOLUZIONE DISPENDIOSA: COMPATTAZIONE DI MEMORIA = solo in caso di estrema urgenza
COSA FA: sposta i processi uno dopo l’altro per compattarli per avere memoria libera in un solo punto
PROBLEMA = impiega tantissimo tempo, causa un calo prestazione evidente pure all’utente
PREMESSA: MONITORARE LA MEMORIA DISPONIBILE
Prima di definire l’algoritmo di allocazione, bisogna identificare un implementazione per LA RICERCA RAPIDA rapida ai frame di memoria
MODALITA A BITMAP

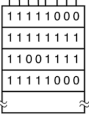
- la memoria è suddivisa in pezzi di dimensione fissa = frame
- ogni frame dell’immagine è mappato bit dopo bit da un registro chiamato bitmap, quindi tiene traccia dello stato di ogni frame bit per bit: il bit allocato vale 1 ed il bit non allocato vale 0 (nell’immagine il bitmap ha le informazioni accatastate uno sotto l’altra, in cima ci stanno le informazioni riferite al frame A, e noto che 3 bit di questo frame sono liberi. Sotto ho le info per il frame B e così via).
PROBLEMI
- non riesco a distinguere quando partono e finiscono i processi nel caso in cui sono contigui
- scomodo e complesso
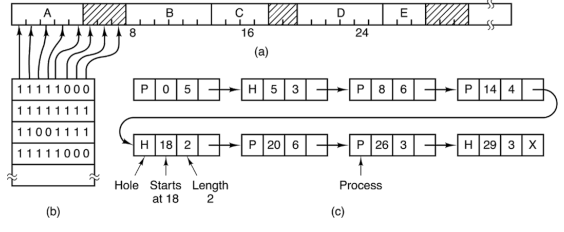
MODALITA’ A LINKED LIST
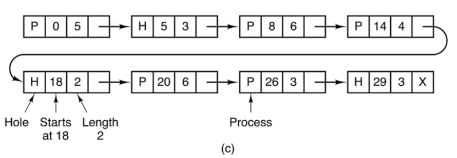
STRUTTURA
OGNI FRAME DI MEMORIA è MAPPATO DA UNA LISTA LINKATA DI TUPLE
Le informazioni specificate in ogni tupla sono:
- Tipo di zona (P per processo o H per hole).
- Indirizzo di partenza della zona (dove inizia in memoria).
- Dimensione della zona (in unità di allocazione, ad esempio in byte o KB).
- Puntatore alla prossima tupla nella lista.
COME FUNZIONA
quando devo allocare un nuovo processo semplicemente vado a cercare un elemento di questa lista che abbia un’intestazione di tipo H e una dimensione sufficiente da soddisfare la mia richiesta
- Quando un processo richiede meno memoria rispetto alla dimensione della zona disponibile.
- Una zona allocata per il processo
- Una nuova zona "hole" (
H)
La zona originale viene divisa in due nuove zone:
ANALISI
Buon compromesso tra complessità e praticità
ALGORITMI DI ALLOCAZIONE
PRIORITà = TEMPO
FIRST FIT

- ANALISI = veloce ma causa frammentazione molto alta
NEXT FIT → first fit + “orologio”

- ANALISI = all’inizio è più lento del FF ma complessivamente è più veloce e l’allocazione più uniforme
PRIORITà = SOLUZIONE MIGLIORE
PRIORITà = GESTIRE L’ALLOCAZIONE DINAMICA P.2 (struttura memoria)
RISOLVO FRAMMENTAZIONE ESTERNA COL DEMANG PAGING (meccanismo di allocazione dinamica)
Nel momento in cui eseguo un programma, i processi nn necessari sono inseriti NON nella memoria fisica RAM bensì nella memoria virtuale, in cui il processo ha l'illusione di avere a disposizione tutta la memoria che gli serve, anche se fisicamente non è così.
- In questo modo il sistema assegna blocchi di memoria al processo solo quando effettivamente servono, man mano che il processo accede a determinate parti della memoria, quindi in base agli accessi della CPU
- la memoria virtuale è suddivisa in pagine e la memoria fisica in frames, una pagina (come i frame) non copre necessariamente un intero processo.
FILE SWAP
- Il campo che non si caga nessuno: quando la RAM è insufficiente, il sistema operativo usa effettivamente spazio di memoria secondaria (come il disco rigido o l'SSD) per "estendere" la RAM. Questo spazio è riservato nel cosiddetto file di swap (o page file) sul disco.
- Quando fa Swap out? Se la RAM è piena e un altro processo ha bisogno di memoria, il sistema operativo libera spazio in RAM. Per farlo, identifica le pagine meno usate (o inattive) e trasferisce il contenuto nel file di swap sul disco. Lo spazio creato può essere usato da altri processi o da altre pagine dello stesso processo.
- Quando fa Swap-in?: trasferisce la pagina dalla memoria secondaria (disco) alla RAM
- Se il sistema ha nuovamente bisogno di una pagina o ne acrà probabilmente bisogno secondo il principio di località, il sistema operativo: fa swap out dei processi meno attivi per fare posto in RAM ai processi a cui si necessita di un accesso più veloce
- il file swap ha un limite e superato questo limite si possono verificare rallentamenti o il rifiuto di nuovi processi
COME AVVIENE IL PROCESSO DI SWAP-IN E SWAP-OUT?
RICHIESTA CPU
La CPU consegna alla MMU l’indirizzo virtuale del processo che gli serve
la MMU deve tradurre l’indirizzo virtuale nell’indirizzo fisico da cui effettivamente prelevare il processo
- la MMU è un pezzo di hardware
TRADUZIONE MMU
La MMU trova i dati per il processo grazie alla tabella delle pagine (gestita appunto dalla MMU) che
- tiene traccia della posizione effettiva dei dati per ogni pagina virtuale
- specifica se essa è caricata in un frame della RAM o se è stata spostata nel file di swap.
SINTESI STEP DOPO STEP ALLOCAZIONE PAGINA
Richiesta della CPU
- La CPU richiede un processo consegnando alla MMU l’indirizzo virtuale
- non sa se la pagina è caricata in RAM o nel file swap. Quindi necessita di traduzione MMU
Divisione dell'Indirizzo Virtuale
- La MMU divide l'indirizzo virtuale in Numero di Pagina Virtuale (ID) e Offset.
- TLM miss(prima fase di rallentamento = accesso alla tabella in RAM) / hit
Accesso alla Page Table
- Verifica il flag di presenza per determinare se la pagina è in RAM.
- La MMU usa l'ID per accedere alla voce corrispondente nella Page Table, l’ID è riferito all’intera pagina.
- La Page Table mappa intere pagine virtuali a frame fisici (ci sono diverse implementazioni, tutte fanno uso dell’ID)
- Ottiene l'identificativo del frame fisico dalla Page Table
- Ogni frame ha un identificativo univoco (numero di frame) che indica la sua posizione all'interno della RAM
FLAG = 1 → la Pagina è in RAM (SOFT Miss)
- Calcola l'indirizzo fisico combinando l'identificativo del frame con l'offset.
- offset per trovare l’istruzione di partenza all’interno del frame
- La CPU accede alla specifica istruzione del processo (da cui partirà l’esecuzione) in RAM utilizzando l'indirizzo fisico.
FLAG = 0 → la Pagina non è in RAM (HARD Miss) **🐌🐌
- il flag di presenza in tal caso da valore 0, indicando che la pagina NON è attualmente in RAM → si genera una trap di page fault → seconda fase di rallentamento = swap-out(+page out) e page-i
- il processo passa in stato di blocked, per effettuare il caricamento
- SWAP-OUT(se necessario): È l'operazione di spostamento dell'intero processo (o di una sua parte) dalla RAM al disco per liberare memoria fisica.
- scelta di una vittima: qui gli algoritmi
- PAGE OUT: operazione I/O di scrittura su disco di una pagina modificata che deve essere rimossa dalla RAM → solo se ci sono modifiche
- SWAP-IN È l'operazione di ricaricamento di un processo (o di una sua parte) dalla memoria di swap (disco) alla RAM per riprendere l'esecuzione.
- PAGE-IN: operazione I/O di lettura dal disco per caricare in RAM una pagina richiesta che non è attualmente presente → avviene sempre per eseguire swap-in
- La Page Table viene aggiornata per riflettere la nuova posizione della pagina, e la TLB può essere aggiornata per accelerare gli accessi futuri a quell’indirizzo.
- ROLLBACK + READY:
- Il sistema operativo effettua un ROLLBACK dell'istruzione che ha causato il page fault, ripristinando il contatore del programma (PC) in modo che l'istruzione venga rieseguita dall'inizio. (Sta volta con il pezzo di codice in RAM)
- il processo viene rimesso nello stato di "ready” pk il page fault ha esaurito il suo quanto di tempo
- Quindi la MMU ripete la traduzione dell'indirizzo virtuale (pk lo scopo era individuare la posizione in RAM ma nn era nemmeno in RAM se c’è hard miss)
CHIAREZZA
- Se necessario si fa swap-out e page-out, poi si fa necessariamente swap-in e quinci page.in
ALTRI DETTAGLI
- Memoria virtuale e memoria fisica non sono necessariamente di uguale dimensione.
- però se il byte che mi interessa è in posizione 80 nella pagina, allora è in posizione 80 anche nel frame finchè entrambi condividono lo stesso valore di indirizzo.
- La page table non contiene unicamente l’ID, il flag e l’identificatore del frame, non al giorno d’oggi. Altri elementi sono:
- bit di protezione: posso associargli dei livelli di protezione. Ad esempio, si può solo scrivere, o solo leggere, o scrivere
e leggere. - Read (R): Permette la lettura dei dati dalla pagina.
- Write (W): Permette la scrittura o modifica dei dati nella pagina.
- Execute (X): Permette l'esecuzione di istruzioni contenute nella pagina.
- Combinazioni: Le pagine possono avere combinazioni di questi permessi (es. solo lettura, lettura e scrittura, ecc.).
- Il bit di modifica: indica se il contenuto di una pagina è stato modificato da quando la pagina è stata caricata in RAM, in caso affermativo salva una copia aggiornata anche nel disco (memoria virtuale)
- Il bit di riferimento: indica se una pagina è stata acceduta (letta o scritta) di recente. Implementazione del principio di località, in quanto aiuta il sistema operativo a tenere traccia delle pagine più utilizzate per ottimizzare la gestione della memoria.
Tipi di Permessi(già affrontati)
PROBLEMA 1(DOPPIO ACCESSO ALLA RAM)
- Si ricorda che la memoria virtuale risolve il problema della frammentazione esterna.
- In ogni caso, la Page Table si trova dentro la RAM ed è gestita dal kernel. Questo fa sii che il processo di traduzione richiede un doppio accesso alla RAM, rallentando il processo:
- Accesso alla Page Table in RAM per la traduzione: La MMU deve verificare nella Page Table l'associazione tra il numero di pagina virtuale e il frame fisico corrispondente. Questo è il primo accesso alla RAM.
- Accesso al dato effettivo in RAM: Dopo aver ottenuto l’indirizzo fisico completo (identificativo del frame + offset), la CPU può finalmente accedere al dato effettivo richiesto in RAM.
SOLUZIONE (TLB) **🐌🐌
- La MMU ha al suo interno una cache chiamata TLB in cui memorizza le coppie pagina-frame più richieste al momento
- se non ha una coppia, deve accedere alla Page Table in RAM
- se la pagina nn è in TLB (TLB miss) → prima fase di rallentamento
PROBLEMA 2 (ottimizzare la memoria)
Page Table a Singolo Livello: Allocazione Completa
- Con una Page Table a singolo livello, c'è una voce per ogni possibile pagina nello spazio di indirizzamento virtuale del processo, anche per quelle pagine che il processo non usa mai.
- le pagine mappano tutti i processi ma nn per questo devono stare tutti in RAM
- Questo significa che, in un sistema con un indirizzamento virtuale ampio (es. 32 o 64 bit), la Page Table a singolo livello deve essere molto grande, anche se una buona parte della memoria virtuale non viene mai utilizzata.
- Risultato: Un’enorme quantità di memoria RAM viene sprecata perché la tabella contiene voci per pagine inutilizzate.
SOLUZIONE (PT a più livelli)
Page Table a Più Livelli: Allocazione su Richiesta
Spezzare la Page Table in più livelli permette di allocare memoria solo per le pagine che vengono effettivamente usate, le altre rimangono su disco.
Ecco come funziona:
Divisione dell’Indirizzo Virtuale:
- Si divide l'indirizzo virtuale in più parti.
- Un indice per il primo livello (prima parte dell'indirizzo).
- Un indice per il secondo livello (seconda parte dell'indirizzo).
- Un offset (posizione specifica all'interno della pagina).
Ad esempio, con una Page Table a due livelli, l'indirizzo virtuale è diviso in:
Allocazione su Richiesta delle Tabelle di Secondo Livello:
- Il primo livello della Page Table ha solo un elenco di puntatori che indicano quali tabelle di secondo livello esistono
- Le tabelle di secondo livello vengono allocate solo se il processo accede a indirizzi virtuali specifici che necessitano di quella tabella.
- Se una parte dello spazio di indirizzamento virtuale non viene utilizzata, la relativa tabella di secondo livello non viene allocata, risparmiando memoria.
QUESTO RISOLVE ANCHE UN ALTRO PROBLEMA (SPRECO DI SPAZIO ALL’ULTIMA PAGINA SE è GRANDE)
Frammentazione Interna: Si verifica quando una pagina di memoria è allocata ma non viene utilizzata completamente. (Si distingue dalla frammentazione esterna che si verifica quando allocando i processi si creano spazi vuoti inutilizzabili).

Questo si verifica quando le pagine sono troppo grandi:
- recap: nn c’è corrispondenza univoca pagina - processo
- Pagine più grandi riducono la dimensione della Page Table “a singolo livello” ma aumentano il rischio di frammentazione interna.
- Pagine più piccole riducono la frammentazione interna, ma richiedono una Page Table “a singolo livello” più grande, con una voce per ciascuna delle numerose pagine.
SOLUZIONE
Grazie alla Page Table a più livelli, puoi permetterti di usare pagine più piccole per ridurre la frammentazione interna senza preoccuparti troppo dell'aumento delle voci nella Page Table, poiché la struttura a più livelli aiuta a controllare e ottimizzare lo spazio utilizzato per rappresentare queste voci.
PAGE TABLE INVERTITE e funzionamento STEP DOPO STEP (soluzione)
Scopo della Tabella di Hashing Invertita
- VANTAGGI
- la tabella sta su disco quindi è più veloce l’accesso
- il sistema di ricerca è più veloce
- In una Page Table tradizionale, c'è una voce per ogni pagina virtuale. Questo significa che la dimensione della Page Table cresce proporzionalmente al numero di pagine virtuali, il che può diventare ingestibile nei sistemi con spazi di indirizzamento molto grandi.
- Una Tabella di Hashing Invertita, invece:
- Contiene una voce per ogni frame, NON per ogni pagina virtuale. Quindi un indice delle pagine fisiche (hash) a cui si possono associare molteplici pagine virtuali (lista collegata)
- ma nonostante ciò mappa cmq tutte le pagine, con un algoritmo di hashing
- una pagina fisica può mappare differenti pagine virtuali ma una sola può accedervi
- Mappa una pagina fisica al corrispondente Page ID virtuale
- il processo può essere mappato con più pagine.
- Se inserisco una di queste pagine avviene una copia di una pagina del processo.
- Usa un algoritmo di hashing per tradurre rapidamente un indirizzo virtuale in un indirizzo fisico.
Richiesta di Traduzione dalla CPU
- La CPU invia alla MMU una richiesta di traduzione di un indirizzo virtuale in un indirizzo fisico.
- recap: questo indirizzo virtuale comprende sia l'ID della pagina fisica sia l'offset all'interno di quella pagina, poiché la CPU vuole accedere a uno specifico byte da cui partire l’esecuzione del processo(frame)
Calcolo dell'Hash
- La MMU estrae l'ID della pagina virtuale, dall'indirizzo virtuale ed è usata dalla funzione di hash per determinare l'indice nella tabella hash corrispondente al frame che mappa la pagina virtuale che sto cercando
Scansione della Lista Collegata
- La MMU accede all’indice nella tabella hash corrispondente all'indice calcolato → quindi ha pure ottenuto l’id del frame per identificare la posizione in RAM
- Se all'indice corrisponde una lista collegata (collisioni di hash), la MMU scorre la lista e identifica la pagina richiesta dalla CPU confrontando l’ID dell’indirizzo virtuale ricevuto con tutti gli ID nella lista
- ID/indirizzo del frame fisico
- Flag di presenza (Present Bit) della specifica pagina
- quindi se la flag è a 0, sarà trasferito in RAM se nn lo era, altrimenti si passa direttamente alla traduzione
- Le collisioni implicano che più pagine si associano allo stesso hash, ma non rappresentano un problema significativo perché, se la funzione di hash è ben progettata, le liste saranno brevi. La MMU utilizza l'ID di pagina virtuale originale per trovare la corrispondenza esatta nella lista
- se la funzione di hashing è basato su un buon algoritmo, le pagine saranno omogeneamente distribuite tra gli indici della tabella.
- Quindi se avessi una sola lista lunghissima, sarebbe come avere una page table a singolo livello
Ogni voce nella Tabella di Hashing Invertita contiene quindi:
Formazione dell'Indirizzo Fisico Completo
- La MMU combina l’ID frame (ottenuto dalla tabella di hash) con l'offset (ottenuto sempre dalla CPU) per formare l'indirizzo fisico completo riferito al dato da cui eseguire il processo
- quindi finisce e informa la CPU
- L'indirizzo fisico è considerato completo quando si riferisce allo specifico byte che la CPU sta cercando. Sebbene la CPU fornisca un indirizzo virtuale (pagina), questo include anche l'offset necessario per risalire all'indirizzo fisico esatto (byte) desiderato.
OSSERVAZIONI
- "cornice di pagina" è sinonimo di "frame"
- mappare è sinonimo di allocare in RAM in diversi casi, nn solo localizzare
- Mappare significa allocare una pagina virtuale nella RAM.
- I sistemi operativi moderni usano le Hash Table ma non agganciano a un elemento una lista, ma un albero in modo tale da arrivare all’elemento che interessa più velocemente
TOTALE RALLENTAMENTI NEL CASO PEGGIORE:
- TLB miss
- Flag = 0
 Made with Bullet
Made with Bullet