INFO DI BASE: qui
Implementazione del File System
- Prospettiva dell’Utente: Gli utenti si concentrano su aspetti come i nomi dei file, le operazioni disponibili, la struttura dell’albero delle directory e altre questioni legate all'interfaccia.
- Prospettiva del tecnico: gestione dell memoria, efficienza e affidabilità nel funzionamento del sistema.
L’implementazione di un file system richiede quindi di bilanciare diversi fattori tecnici per garantire che sia funzionale, rapido e sicuro per l’utente finale.
Accensione computer
SUNTO
BIOS
settore 0 = (bootloader primario → tabella con partizione attiva flaggata)
boot sector = (bootloader secondario → kernel)
Quando un computer si accende, la CPU esegue una serie di passaggi per avviare il sistema operativo
- Premi il pulsante di accensione: fornisce energia ai componenti hardware del PC, quindi avvia la CPU e la scheda madre
- la CPU esegue il BIOS nella scheda madre
- il BIOS è un software nella scheda madre di un computer
- La scheda madre è il componente principale di un computer, su cui si collegano e comunicano tutti gli altri componenti hardware.
cosa fa il BIOS?
- Il BIOS individua il disco fisso e carica in memoria, un settore del disco chiamata Master Boot Record (MBR) o settore 0, il cui codice è chiamato bootloader primario
cosa fa il bootloader primario?
- esamina al suo interno la tabella delle partizioni per trovare ed eseguire la partizione contrassegnata come partizione attiva (flag), ossia quella designata per l'avvio del sistema operativo, pk il primo settore di quella partizione contiene il bootloader secondario
- i dischi possono essere suddivisi in una o più partizioni, ciascuna con un proprio file system indipendente → REGISTRATI IN UNA TABELLA DEL SETTORE 0
- ogni partizione si compone di blocchi fisici chiamati settori
- nei sistemi Linux in specifico: ogni partizione ha come primo settore il boot block, nel caso più specifico della partizione designata per l'avvio del sistema operativo (flag), questo si chiama boot sector
- in seguito carica in memoria il boot block/boot sector (settore di avvio) della partizione attiva.
- il cui codice è chiamato bootloader secondario
cosa fa il bootloader secondario?
- carica in memoria il kernel
cosa fa il kernel?
- Il kernel prende il controllo del sistema.
- Inizia l'inizializzazione dei componenti hardware e delle risorse di sistema, il primo processo del kernel è chiamato Init
- primo processo: qui
Layout della Partizione
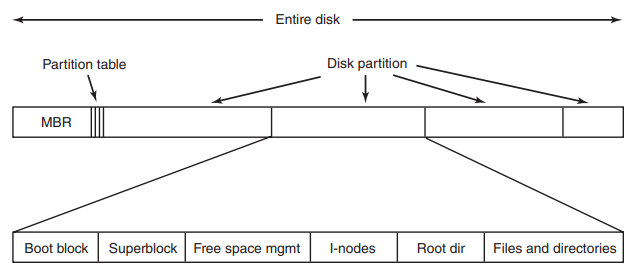
Elementi di una Partizione
- i dischi possono essere suddivisi in una o più partizioni (sezioni logiche), ciascuna con un proprio file system indipendente
- ogni partizione si compone di blocchi fisici chiamati settori o data block
CALLSSIFICAZIONE SETTORI
- Ogni partizione inizia con un boot block
- settore speciale che contiene codice di avvio, ma viene usato solo quelllo della partizione attiva (boot sector)
- Super block: contiene i parametri principali del file system
- Blocco per la Gestione dello Spazio Libero: Include informazioni sui blocchi liberi della partizione (file system)
- I-nodes: qui
Elementi veri e propri → la partizione ingloba un file system
- posizione della Root Directory
- File e Directory: Il resto della partizione è occupato da i file e dalle directory
ACCORGIMENTI IMPLEMENTATIVI PER L’OTTIMIZZAZIONE
4.3.2 implementazione per ricerca veloce blocchi di files(settori) → ricerca veloce dei blocchi, da distinguere da questo
Allocazione contigua
L'allocazione contigua è uno schema semplice per la gestione dello spazio su disco, in cui ogni file viene memorizzato come una sequenza continua di blocchi.
- Ad esempio, un file da 50 KB su un disco con blocchi da 1 KB occuperà 50 blocchi consecutivi.
- Questo metodo richiede di ricordare solo due informazioni: l'indirizzo del primo blocco e il numero di blocchi consecutivi del file da leggere.
- l'allocazione contigua è utilizzabile su supporti ottici come CD-ROM e DVD, dove la dimensione dei file è nota in anticipo e non cambia.
Vantaggi dell'allocazione contigua
- semplicità di implementazione
- alte prestazioni in lettura
Problemi di frammentazione esterna
- quando file vengono rimossi, lasciano spazi vuoti (buchi) su disco, la compattazione costa troppo e spreca spazio
- Per utilizzare i buchi sul disco, è necessario mantenere un elenco degli spazi liberi
lista collegata di blocchi (o free list)
Ogni blocco del file contiene un puntatore al blocco successivo, mentre il resto del blocco è riservato ai dati.
- un file è contenuto in molteplici blocchi
Per evitare un eccessivo carico di I/O e mantenere un equilibrio, è possibile ottimizzare la gestione delle free list:
- Divisione a metà:
- Si carica in memoria metà della lista, in questo modo riduco notevolmente il numero di accesso su disco pk ho metà dei blocchi liberi già in RAM
- quando faccio un certo numero di operazioni sui blocchi liberi della lisa, effettuo la sincronizzazione con i file su disco
- Gestione dinamica:
- Se un processo consuma rapidamente la metà lista in memoria (ad esempio per allocare un file grande), viene semplicemente ricaricata una nuova porzione e quella piena viene sincronizzata sul disco
Vantaggi della lista collegata
- no frammentazione
- i blocchi non sono necessariamente consecutivi grazie ai puntori
- Per identificare un file è sufficiente memorizzare, nella directory, l'indirizzo del primo blocco su disco. Da quel punto in poi, tutti i blocchi successivi possono essere individuati seguendo i puntatori.
SVANTAGGI
accesso casuale → lettura sequenziale che rallenta
una parte del blocco è riservata al puntatore al blocco successivo → la quantità di spazio disponibile per i dati non è più una potenza di due.
FAT (File Allocation Table) → evoluzione della lista collegata di blocchi
FAT (File Allocation Table), tabella interamente in memoria che centralizza al suo interno tutti i puntatori ai blocchi di ciascun file
VANTAGGI
- elimina le limitazioni della lista collegata (accesso casuale, che fa troppi accessi su disco, con i puntatori in RAM, trova il puntatore e fa un solo accesso preciso)
- Ogni catena di puntatori termina con un marcatore speciale, per indicare la fine del file
- l’intero blocco su disco è dedicato ai dati, senza dover riservare spazio per il puntatore
- accesso casuale + veloce pk la tabella riduce il tempo di acceso al disco
DIMENSIONI
Il file viene suddiviso in unità di dimensione fissa chiamate cluster,
Il file viene suddiviso in unità di dimensione fissa chiamate cluster,
- FAT16: Usa 16 bit per identificare i cluster, quindi può indirizzare un massimo di 2¹⁶
- più bit ha a disposizione, più combinazioni possiede, più indirizzi può utilizzare
- FAT32: utilizza 32 bit per identificare i cluster, consentendo di indirizzare fino a 2³². Supporta volumi fino a 2 TB (teoricamente fino a 16 TB, ma con limitazioni tecniche).
Svantaggi della FAT
la tabella occupa spazio in RAM, non è scalabile pk nn può crescere per sempre
I-Nodes: qui
Partendo da un i-node, è possibile individuare rapidamente tutti i blocchi che appartengono a un file.
Vantaggi rispetto alla lista collegata con tabella in memoria
- allocazione dinamica degli I-node, come il demand paging → la CPU accede alla directory corrispondente, trova I-node dalla tabella nome file/I-node dentro il file directory e lo carica in memoria
- L’accesso a blocchi specifici è velocissimo pk l’I-node ha una voce per ogni blocco del file
- Mentre le tabelle in memoria crescono proporzionalmente al numero di blocchi del disco, il numero di i-nodes cresce solo in funzione del numero massimo di file aperti contemporaneamente, indipendentemente dalle dimensioni totali del disco.
Gestione dei file di grandi dimensioni
l’inode ha un numero di indirizzi dei blocchi limite che può memorizzare, sopra il quale, si implementa nell’ultimo indirizzo dell’i-node un puntatore a un blocco contenente ulteriori indirizzi di blocchi su disco.
Puntatori ai blocchi di dati:
- Per file piccoli: i primi 10 indirizzi dei blocchi di dati sono memorizzati direttamente nell’i-node.
- Per file più grandi: un indirizzo nell’i-node punta a un blocco indiretto singolo, che contiene ulteriori indirizzi di blocchi di dati.
- Per file ancora più grandi: esistono blocchi indiretti doppi (un blocco che punta a blocchi indiretti singoli) e blocchi indiretti tripli (un blocco che punta a blocchi indiretti doppi).
Memorizzazione degli attributi dei file → dove?
- nella directory
- nell’ i-nodes, la cui posizione è nella directory
memorizzazione dei nomi di file di lunghezza variabile nella directory→ come?
- riservare uno spazio fisso (ad esempio, 255 caratteri) per ogni nome file, ma questa scelta spreca spazio, poiché la maggior parte dei file ha nomi più corti.
- mantenere le voci della directory (contenenti le info dei file) di lunghezza fissa e spostare i nomi dei file in una heap alla fine della directory
RICERCA VELOCE DEL FILE DELL I-DONE, QUANDO SONO NELLA DIRECTORY ASSOCIATA
- La directory ha una tabella indicizzata nome file → posizione I.node associato
- nome di file = input della funzione di hash
- output = posizione nella tabella
- Uso di una cache per contenere gli I-nodes più richiesti → come la TLB per la MMU
TIPI DI FILE SYSTEM (STRUTTURA)
4.3.5 Log-Structured File Systems → problema del seek time
Collo di bottiglia
Con l'aumento delle prestazioni delle CPU, della capacità della RAM e delle dimensioni dei dischi, rimane un collo di bottiglia, ovvero le operazioni di scrittura e lettura la cui lentezza è causata dal seek time (tempo di posizionamento della testina del disco).
La Soluzione: Log-structured File System (LFS)
LFS sfrutta la crescita della RAM, che permette di soddisfare molte richieste di lettura direttamente dalla cache, riducendo la necessità di leggere frequentemente dal disco. Di conseguenza, le operazioni sui dischi si concentrano principalmente sulle scritture.
Principio base: LFS tratta l'intero disco come un grande log, in cui le scritture vengono effettuate in modo sequenziale alla fine del log, per risparmiare tempo
- Un log è un registro sequenziale di eventi, operazioni o modifiche che vengono salvati in un sistema per tracciare le attività che sono state eseguite
Struttura del Log
Il log(disco) è organizzato in segmenti, ognuno contenente:
- Dati del file: Blocchi di dati associati ai file.
- i-nodes: Metadati che descrivono i file e i loro blocchi
- quindi il segmento contiene tutto il file
- Riassunto del segmento: descrizione del contenuto del segmento.
La suddivisione in blocchi continua ad esistere, ma la logica LOG guarda ai segmenti
Le scritture non vengono registrate immediatamente su disco, ma accumulate in un buffer in RAM. Quando il buffer è pieno, i dati vengono scritti in modo contiguo in un segmento alla fine del log.
PK?
L'obiettivo principale di LFS è ridurre i movimenti della testina del disco, il collo di bottiglia delle prestazioni dei dischi tradizionali. Quando si aggiorna un file:
- File system tradizionali: La testina deve spostarsi nella posizione originale del file, modificare i blocchi e aggiornare i metadati, aumentando i tempi di seek.
- LFS: Tutti i dati aggiornati (blocchi e metadati) vengono scritti alla fine del log in un unico segmento, eliminando i movimenti frammentati della testina che nn serve più
dove trovare un i-node
distribuiti nei segmenti del log → Per localizzarli, LFS utilizza una mappa degli i-nodes, come al solito…
aggiornamenti dopo la modifica
Ogni volta che un blocco viene modificato:
- L’i-node corrispondente deve essere aggiornato per riflettere il nuovo blocco nel nuovo segmento
- La mappa degli i-nodes deve essere aggiornata, pk l’inode di sposta nell’ultimo segmento associato al blocco appena riscritto
garbage collection
Quando il disco è pieno, non è possibile scrivere nuovi segmenti → si usa un thread di pulizia
- Scorre i segmenti per identificare i blocchi e gli i-nodes validi.
- Raccoglie questi dati in memoria.
- svuota i segmenti obsoleti rimasti
- Scrive i dati validi in nuovi segmenti contigui alla fine del log.
quindi i nuovi dati vengono aggiunti in testa al log e i segmenti obsoleti vengono rimossi dalla coda.
- I segmenti obsoleti contengono la versione precedenti alle modifiche aggiornate in fondo al log, vengono quindi riscritti i file su disco mantenendo solo le modifiche recenti
4.3.6 Journaling File Systems → gestire le inconsistenze
Introduzione e differenze strutturali
- LFS (Log-structured File System):
- Il log è l’intero disco.
- Scopo: ottimizzare le prestazioni di I/O, sfruttando scritture sequenziali.
- File System Journal:
- Il journal è il log in questione ed è un’area dedicata del file system (tipicamente una partizione o un file).
- Scopo: Garantire la consistenza e il recupero in caso di crash, registrando operazioni prima di eseguirle.
- Ad esempio, durante l'eliminazione di un file, se il crash avviene a metà dei passaggi (es. liberazione dei blocchi o degli i-nodes), si possono perdere risorse preziose.
Come funziona il journaling
- Registrazione nel journal:
- L’operazione (es. eliminare un file) viene descritta dettagliatamente in una voce di log con tutti i passaggi necessari.
- Questa voce viene scritta nel journal e verificata per garantirne la correttezza.
- Esecuzione dell’operazione:
- Solo dopo che il log è stato registrato correttamente, il file system esegue le operazioni reali (es. eliminazione del file, liberazione di i-nodes e blocchi).
- Cancellazione del log:
- Quando l’operazione è completata con successo, la voce corrispondente nel journal viene rimossa.
- Crash recovery:
- In caso di crash, il file system legge il journal al riavvio.
- Le operazioni incomplete vengono identificate e ripetute fino al completamento, garantendo uno stato consistente.
Caratteristiche fondamentali
Idempotenza delle operazioni
Le operazioni loggate devono essere idempotenti, ovvero ripetibili senza effetti collaterali. Esempi:
- Idempotenti: Aggiornare una bitmap per marcare un blocco come libero.
- Non idempotenti: Aggiungere direttamente un blocco a una lista, poiché potrebbe già essere stato aggiunto.
Transazioni atomiche
Il journaling raggruppa le operazioni correlate in transazioni:
- Una transazione è completata solo se tutte le operazioni vengono eseguite correttamente, altrimenti potrebbe causare inconsistenza
- In caso di errore, nessuna delle operazioni del gruppo viene applicata e ricomincia da capo
4.3.7 Virtual File Systems → mappare file system eterogenei
Introduzione ai file system multipli
Molti sistemi operativi supportano file system diversi sullo stesso computer.
- Unificazione di file system separati o remoti per facilitare la gestione
Il concetto di Virtual File System (VFS)
Il VFS è uno strato astratto che separa le operazioni comuni a tutti i file system (esistenti nel disco) dai dettagli specifici di ciascuna implementazione. Il VFS:
Delegazione ai file system concreti:
- Quando un'operazione richiede l'accesso ai dati effettivi memorizzati su disco (ad esempio, leggere un blocco o scrivere un file), il VFS non può eseguire queste operazioni direttamente.
- Il VFS delega queste operazioni al file system concreto
- Ogni file system concreto deve implementare una serie di funzioni standard che il VFS può chiamare per interagire con il disco.
- Dal punto di vista degli utenti, tutto sembra un unico file system, non ha idea delle operazioni di delega che vengono effettuate
Registrazione e montaggio dei file system
Quando il sistema si avvia:
- Il file system root (concreto) viene registrato presso il VFS.
- Durante la registrazione dei file systems ciascuno di essi fornisce una lista di funzioni (per ciascun file system monetato) che il VFS può chiamare per eseguire operazioni come leggere, scrivere o eliminare file.
- il VFS utilizza queste informazioni per sapere come interagire con ogni file system montato.
Richiesta di apertura di un file → DELEGA AL FS CONCRETO CREANDO IL v-node→
- Creazione V-node
- Il file system concreto fornisce la lista delle operazioni disponibili, ma non sa a quali file applicarle.
- Il v-node è una struttura che memorizza le operazioni associate al file a cui so vuole accedere
- serve proprio per associare un file specifico alle operazioni corrette (il VFS ha la lista di operazioni ma nn sa quali servono per determinati files, quindi il v-node racchiude le operazioni, tra quelle in lista, riferite ad ogni file)
- In futuro (appena prossimo), quando il processo esegue un’operazione come
read, il VFS: - Consulta la tabella dei file descriptor per individuare il v-node associato per eseguire la delega di operazioni quali scrittura e lettura richiamando le funzioni salvate nel v-node
4.5.2 The UNIX V7 File System
- Struttura del file system → albero che parte dalla directory radice (
/)
- in ogni directory: tabelle che associano il nome del file al numero di i-node
- Ogni directory include due entry speciali:
.: Puntatore all’i-node della directory corrente...: Puntatore all’i-node della directory genitore.- Queste entry vengono create automaticamente quando una directory viene generata. Per la directory radice (
/), l’entry..punta a se stessa.
Dove vengono memorizzati gli attributi di un file? → nell’I-node
 Made with Bullet
Made with Bullet