TERMINOLOGIA
- IPC = Inter-Process Communication: va gestito per coordinare le operazioni sulle risorse condivise
- RACE CONDITION: condizione in cui più processi sono in competizione per una risorsa in modo non sincronizzato, in questo scenario lavorano sulla stessa risorsa quasi contemporaneamente e senza controllo causando inconsistenze, può causare deadlock
- REGIONI CRITICHE: zone di codice in cui un processo tenta di accedere a una risorsa condivisa. Possono essere posizionati in differenti punti del codice
DEADLOCK
- Scenario in cui ogni processo sta aspettando un evento (rilascio di una risorsa) che può essere causato solo da un altro processo dello stesso insieme.
- Nessun processo può proseguire, causando uno stallo permanente.
4 CONDIZIONI DI COFFMAN PER GARANTIRE CONSISTENZA DEI DATI ALL’INTERNO DI REGIONI CRITICHE
- SI MUTUA ESCLUSIONE
mai implementare processi che usano contemporaneamente la stessa risorsa
- NO ASSUNZIONI
- velocità dei processi, per prevedere se può essere interrotta o meno l’accesso ad una risorsa condivisa da un processo (operazione atomica). Pk non si può supporre la velocità con cui un processo opera su una risorsa ma neanche in generale
- numero di CPU pk supporre di avere molteplici CPU per eseguire processi in parallelo potrebbe portare a errori di progettazione, se il processo è eseguito nell’elaboratore sbagliato
- NO INTRALCIO
mai implementare processi in cui, un processo A, al di fuori della regione critica sia d’intralcio a un processo B che deve entrare all’interno della regione critica
- NO STARVATION: attesa indefinita del proprio turno ad usare una risorsa condivisa
Case study, scenario in cui gestire la sincronizzazione
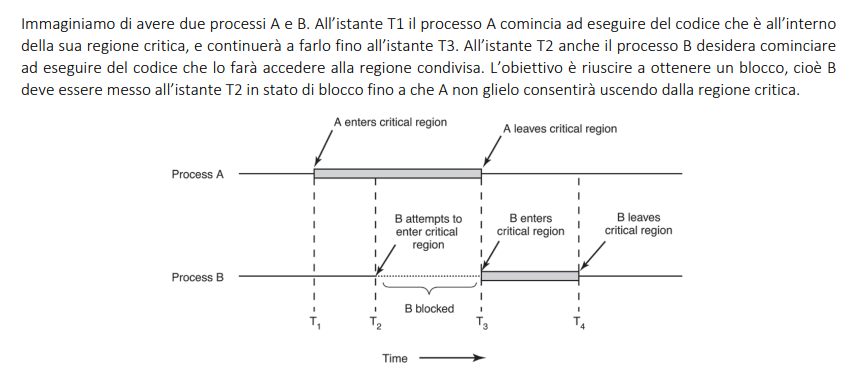
DISABILITO GLI INTERRUPT (busy waiting: verifica che la CPU finisce con il processo per riattivare gli interrupt)
PK: in assenza di interrupt ho la garanzia che la CPU non si arresta in alcuna situazione ed esegue il processo A fino alla fine, quindi il processore B non può fare nulla
PROBLEMI: crea instabilità nel sistema, esempi:
- in uno scenario simile, perdo i benefici della multiprogrammazione e del time-sharing, pk l’allocazione dinamica avviene proprio per mezzo di interrupt di clock
- se avessi un sistema multi-CPU, il primo può risultare occupato ad eseguire il processo nella regione critica ed il secondo può sempre causare race condition. Se invece disabilitassi l’interrupt per tutti i proceessori, causerei un calo drastico delle prestazioni del computer
METODO BUSY WAITING = tenere occupato il processo per tutto il tempo dell’attesa, in svariati modi
VARIABILI DI LOCK
la regione critica contiene una variabile booleana che specifica se è occupata o meno. Il thread in attesa continua a controllare se la regione si è liberata
PROBLEMA
- non è transazionale: più thread possono leggere lo stesso stato "libero" e tentare di entrare contemporaneamente
SOLUZIONE
- TSL
TSL (Test-and-Set Lock)
TSL = istruzione che una componente della CPU esegue in un solo passaggio
- Test: legge il valore della variabile di lock riferita a una regione critica
- Set: la imposta a 1 (che significa "occupato") o 0 (”libero”)
è la base di implementazione di semafori, mutex e altre strutture di sincronizzazione
I 2 metodi seguenti, sotto seppur con vari difetti, possono essere implementati anche con linguaggi di alto livello
ALTERNANZA STRETTA (busy waiting: verifica che turn sia 0 oppure 1 per entrambi i processi)

- i 2 processi eseguono un ciclo infinito:
while(TRUE)
turn= variabile di lock- Il processo (a) entra nella sua regione critica solo quando
turnè 0. - Il processo (b) entra nella sua regione critica solo quando
turnè 1 - il processo aspetta il suo turno per entrare e quando esce pone la sua variabile locale a 1 segnando l’accesso al processo b
- l’implementazione dei 2 processi è diversa pk entrano a condizioni opposte, quindi la logica è rigida e non facilmente generalizzabile su più processi
- viola la terza regola di Coffman
- ALGORITMO DI PETERSON
FUNZIONAMENTO
Ogni processo controlla il valore di
turn prima di entrare nella propria regione critica:PROBLEMA

SOLUZIONE
ALGORITMO DI PETERSON (busy waiting: si verifica nel punto in cui il processo è interessato ad entrare nella sezione critica e deve aspettare che la variabile turn gli dia accesso)
L'algoritmo usa due variabili globali:
turn: Indica di chi è il turno assume il valore dell’ultimo processo ad aver fatto mostra di interesse per la risorsa condivisa, quindi specifica chi ha la priorità
interested: array booleano che ha una cella per ciascun processo che compete per l'accesso alla regione critica.
FUNZIONAMENTO
- chiamata alla funzione
enter_region: quando il processo A vuole entrare nella regione critica, deve dichiarare che è interessato a farlo interested[A] = truenon garantisce l’accesso regione criticaES. turn = B→ se anche B è interessato, ottiene la priorità
“Array in posizione A = true”
- chiamata alla funzione
leave_region: quanto il processo vuole uscire interested[B] = false.
Il prossimo processo ad avere la priorità è l’ultimo ad averne espresso il desiderio
METODO SLEEP AND WAIT (system call)
Il busy waiting anche se ha migliorato nel tempo l’implementazione algoritmica, rimane concettualmente uno spreco di risorse.
Sleep and Wait è uno strumento che il processo usa per autosospendersi finchè nn ha accesso alla regione critica.
PREMESSA
Questo metodo si basa sull'uso di due system call
sleep: sospende l'esecuzione del processo fino a quando non viene "svegliato".
wakeup: sveglia un processo precedentemente sospeso
che sincronizzano un consumatore ed un produttore all’accesso ad un buffer.
La variabile
count conta il numero di oggetti contenutiAZIONI
- produttore: aggiunge un oggetto e incrementa il count di 1
- consumatore: preleva un oggetto e decrementa la variabile di 1
CALL SYSTEM
- Il consumatore si addormenta (esegue
sleep) quando il buffer è vuoto (cioècount = 0) - Rimane in stato "dormiente" fino a quando il produttore lo sveglia con la chiamata
wakeupportandocountda 0 a 1
- Il produttore si addormenta (esegue
sleep) quando il buffer è pieno - Rimane dormiente fino a quando il consumatore consuma un elemento, riducendo
countda N a N-1.
PROBLEMA
Non è transazionale: il test&set di un produttore che verifica il count e agisce può essere compromesso da un altro consumatore o produttore
SOLUZIONE
MECCANISMI DI SICRONIZZAZIONE
- 2 semafori
- empty : inizializzato a N → indica quanti item vuoti ci sono
- full : inizializzato a 0 → indica quanti item occupati ci sono
- 1 mutex: inizializzato a 1 → gestisce l’accesso alla regione critica
FUNZIONAMENTO
Prima di che produttore/consumatore acceda al buffer, si verificano 2 operazioni:
semaforo
il produttore decrementa il semaforo empty (n spazi VUOTI)
- Se
empty == 0→ non ci sono spazi liberi → produttore insleep
- semaforo implementato con un canale in Go
- Quando un consumatore consuma un elemento, incrementa
empty, liberando uno spazio.
il consumatore decrementa il semaforo fulll (n spazi PIENI)
- full indica il numero di spazi occupati
- Se
full == 0→ non ci sono spazi occupati → consumatore insleep
- Quando un produttore inserisce un elemento, incrementa
fullperché c'è un elemento in più disponibile.
mutex
- se vale 1 significa → si decrementa e consente l’accesso
- se vale 0 → il processo va in
sleep
I semafori e i mutex sono entrambi meccanismi di sincronizzazione che usano una variabile count
Mutex: ammette l’accesso ad un processo alla volta
Semaforo: ammette l’accesso fino a N processi alla volta, se N=1 è come unmutex- Se
count> 0: - Il processo può entrare nella regione critica.
- Decrementa il valore del semaforo di 1 (consuma una risorsa).
- Se
uguale= 0: - Non ci sono risorse disponibili.
- I l processo viene messo in
sleepfinché il semaforo non sarà di nuovo maggiore di 0 - Incrementa il valore del semaforo di 1 (libera una risorsa).
- Se ci sono processi in attesa, uno di questi viene svegliato (
wakeup) e può riprendere l’esecuzione. - Incrementa
count. - in presenza di processi in attesa, uno viene svegliato
- sono un po’ difficoltosi da gestire in un linguaggio ad alto livello
Controlla il valore del
count con 2 operazioniDown: quando il processo tenta l’acceso alla risorsa
Up: quando il processo cede la risorsa
Monitor
Un monitor è una struttura che racchiude:
- risorse condivise
- procedure che possono essere eseguite dai processi per accedere alle risorse condivise
- meccanismo di sincronizzazione automatica
DIFFERENZA
- Un semaforo è un meccanismo a basso livello, dove il programmatore deve gestire manualmente il controllo dell'accesso
- Un monitor invece è un costrutto ad alto livello che automatizza la sincronizzazione:
- Quando un processo entra nel monitor, altri processi vengono automaticamente messi in attesa.
- Quando il processo esce, un altro processo in attesa può accedere.
Problema delle Barriere (risolvibile con i semafori)
- Contesto: Si verifica quando più processi devono sincronizzarsi per raggiungere uno stesso punto di esecuzione comune.
- Esempio:
- In un riproduttore multimediale:
- A: Decodifica il video.
- B: Decodifica l’audio.
- C e D: Generano sottotitoli in diverse lingue.
- Ognuno di questi processi ha tempi diversi di esecuzione ma devono tutti sincronizzarsi per rappresentare lo stesso frame al momento giusto.
- Meccanismo di sincronizzazione:
- Viene usata una "barriera" che ferma tutti i processi fino a quando tutti non sono pronti.
- Solo quando ogni processo ha completato il suo lavoro per il frame corrente, la barriera permette loro di proseguire al frame successivo.
- Semafori: Sono utilizzati per gestire questa sincronizzazione.
Problema dei 5 Filosofi (problemi in risorse condivise limitate)
- Ci sono 5 filosofi seduti a un tavolo, ciascuno con un piatto e una forchetta alla sua destra e alla sua sinistra.
- Ogni filosofo ha bisogno di entrambe le forchette per mangiare.
- Se tutti prendono contemporaneamente la forchetta di destra, nessuno può prendere la forchetta di sinistra, causando un deadlock (blocco del sistema).
- Problema da risolvere:
- Evitare situazioni di deadlock o starvation (filosofi affamati che non riescono mai a mangiare).
- Soluzione
Invertendo l’ordine di acquisizione delle forchette per un solo filosofo, si rompe la circolarità
IPC IN GO
INCONSISTENZE BANCA AL VARIARE DEL thinkTime
RECAP
- Broker:
- Prelevano una certa quantità (
qtt) dal conto. - Dopo un ritardo (
thinkTime), rimettono la stessa quantità nel conto.
- Observer: Una goroutine che monitora periodicamente (
watchTime) il saldo del conto e lo stampa.
OBIETTIVO
Analizzare cosa succede al saldo del conto se unicamente tra prelievo e restituzione del broker metto
thinkTime> 0
thinkTime= 0
- no
sleep
RISULTATO
Senza sleep
- Il sistema non cattura le race conditions, perché il compilatore di Go a capito che l’operazione di togliere e mettere è invariabile, quindi nn fa nulla e lo rende quindi atomico
Con sleep e thinkTime = 0:
- la System Call forza l’arresto della CPU mettendo in grande crisi il sistema
MUTEX ai brokers
- Cosa fa:
- Viene utilizzato un mutex per sincronizzare l'accesso al conto bancario. Questo garantisce che solo un broker alla volta possa modificare il saldo.
- L'osservatore non usa il mutex, quindi può leggere il saldo mentre i broker stanno modificandolo
- correzione parziale delle inconsistenze
- Output:
- Il saldo mostrato dall'osservatore è generalmente 999, perché osserva il saldo mentre uno dei broker ha già prelevato ma non ancora reinserito l'importo.
- Se si imposta il
thinkTimea 0 (nessuna pausa tra prelievo e deposito), il saldo rimane stabile a 1000
Mutex al conto
- Cosa fa:
- Si migliora la progettazione attaccando il mutex direttamente al conto bancario
- Output:
- Il comportamento è simile a quello del primo caso: l'output alterna tra 999 e 1000, a seconda del
thinkTime.
 Made with Bullet
Made with Bullet