3 MODELLI CONCETTUALI PER IL TIME SHARING
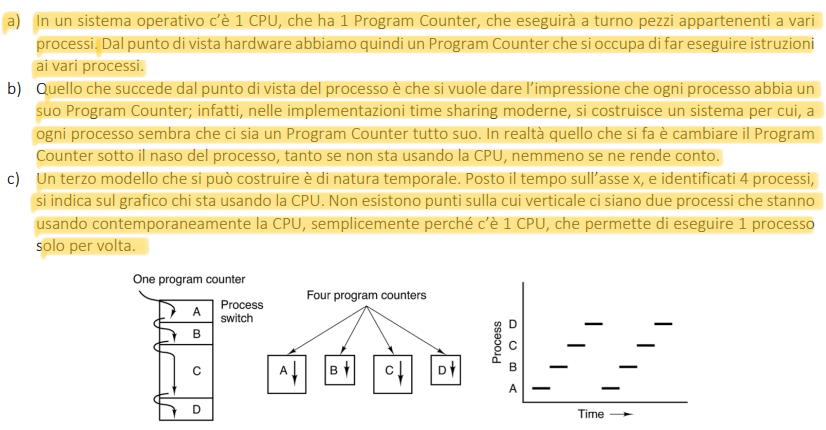
- HARDWARE: PC fa switch periodici tra i processi
- PROCESSO
Il sistema operativo mette in pausa il processo salvandone lo stato (incluso il Program Counter) all’interno del PCB finché non arriva di nuovo il suo turno per usare la CPU.
Il processo nn si accorge di questo meccanismo
- Un grafico con x=tempo ed y=processi
4 MODI PER CREARE UN PROCESSO
- Inizializzazione sistema
init
- System Call
fork
- Richiesta dell’utente
fork
tramite doppio click o l’invio di un testo su un interfaccia apposta (motore di ricerca, terminale, software di vario tipo…)
- Tramite esecuzione di un job in un sistema batch
4 MODI PER TEMINARE UN PROCESSO

VOLONTARIA
- NORMAL EXIT: restituisce 0
- ERROR EXIT: restituisce n numero da 1 a 255 in base al tipo di errore, informando il sistema
INVOLONTARIA:
- Fatal Error: la CPU chiede al S.O. di terminare il processo pk è impossibile da sistemare
- la divisione per 0
- Su richiesta: un processo fa richiesta al sistema operativo di terminare un altro processo
- Task Manager al Browser se nn rispomde
CICLO DI VITA DI UN PROCESSO
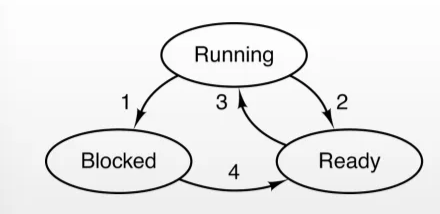
Un processo si divide in 3 stadi principali:
- READY
- (ready) oppure (running - ready): pronto per essere eseguito, sta in lista d’attesa
PRIMA DEL READY
Nel momento in cui un processo usa una
fork, il nuovo processo creato non va subito in stato di ready, ma passa per uno stato intermedio in cui il sistema operativo lo prepara allocando tutte le risorse necessarie.- RUNNING → CPU esegue il processo
- tanti processi in ready ed uno solo in running → politica scheduler
- (running - exit): termina solo in fase di running in modalità kernel, pk lancia la SC
exit: che sia volontaria o meno - dopo la richiesta di terminazione il processo figlio finisce in uno stato intermedio detto zombie, in cui rimane finchè il processore padre non raccoglie le informazioni per la sua terminazione e non effettua la system call
waitche conferma la sua eliminazione.
PROCESSO DI TERMINAZIONE
Da non confondere con
waipid- BLOCKED (stato di attesa)
- (running - blocked): avviene solo in fase di running in modalità kernel pk la System Call Bloccante è eseguita ovviamente quando il processo ha la CPU
- il processo attiva una SYSTEM CALL BLOCCANTE per operazione I/O oppure accesso ad un periferica e non è più considerato dalla CPU momentaneamente
- attesa per preparazione delle risorse → la periferica lancia un interrupt alla cpu quando è pronta
- per ottimizzare lo spazio
- il passaggio allo stato di blocked su disco di un processo avviene quando è in stato di blocked per molto tempo (swap out) L’unica parte del processo che rimane in memoria è il PCB, che serve per lo scheduling.
- al recupero del processo l’utente aspetta più tempo del solito pk prima passa in stato di ready su disco, e quando le risorse sono state preparate, passa in stato di ready in memoria (swap in)
PROCESSO DI BLOCCO
OPERAZIONE SWAP
TRANSIZIONI IMPOSSIBILI
(ready - blocked)
(blocked - running)
COS’è PROCESS CONTROL BLOCK
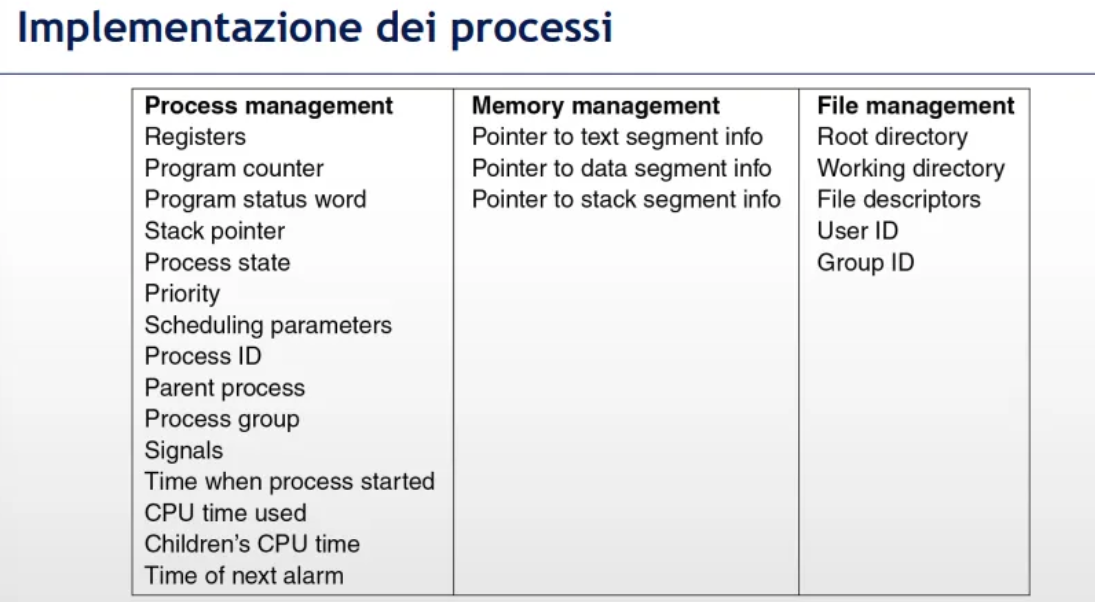
PCB
- struttura dati che contiene informazioni essenziali per il ripristino e la gestione del processo
DOVE SI TROVA
- Nel kernel è presente una tabella chiamata Process Table: tramite Process ID è possibile trovare il PCB del processo corrispondente.
STRUTTURA
Diviso in tre sezioni principali
- Informazioni di gestione processo
- livello di priorità
- stato esecutivo
- PID
- Program Counter
- time slice
- Informazioni di gestione memoria
- puntatori alle 3 sezione di memoria di un processo: qui
- Informazioni sui file associati al processo
- Working directory: specifica la directory corrente in cui il processo sta operando
- Root directory: indica la directory principale del file system a cui il processo ha accesso.
- File descriptors: identificatori numerici che un processo utilizza per riferirsi ai file aperti
- User ID (UID): identifica l'utente proprietario del processo
- Group ID (GID): specifica il gruppo di utenti a cui appartiene il processo
Per consentire ai processi di interagire con il file system del sistema operativo
MULTIPROGRAMMAZIONE E UTILIZZO DELLA CPU
Come lo scheduler ottimizza la CPU?
- cerca di bilanciare 2 tipi di processi, per creare uno scenario in cui mentre i processi I/O-bound attendono risorse, i processi CPU-bound possono essere eseguiti, evitando che la CPU rimanga inattiva
Come?
- definisce la durate del time slice
- definisce l’ordine di priorità: se dopo 2 volte il processo nn ha finito, probabilmente è CPU-bound, gli assegna priorità più bassa
Altre informazioni
- In media, un processo trascorre circa l'80% del tempo in stato bloccato (aspettando risorse come input/output)
- TASSO DI UTILIZZO DELLA CPU
- p → probabilità stato di blocked non attesa
La formula del tasso di utilizzo della CPU esprime la probabilità che almeno un processo sia in esecuzione in un sistema multiprogrammato. È utile per analizzare sua efficienza.

COME VIENE GESTITO UN INTERRUPT → esempio con la multiprogrammazione (int. di clock)
La multiprogrammazione avviene attraverso interrupt di clock
Un interrupt è un segnale che interrompe il normale flusso di esecuzione della CPU per richiedere attenzione immediata ad un altro processo
Quando arriva un interrupt di clock
- il processo non cambia immediatamente stato, ma il suo contesto viene salvato per poter essere ripreso successivamente.
CPU → salvataggio stato corrente del processo
- Program Counter (PC): indica l'istruzione successiva da eseguire.
- Stato del processo: ready, running, blocked.
- Informazioni di gestione della memoria: puntatori allo stack, heap e segmento dati.
- Identificatori di processo: PID, priorità, stato.
- salvataggio all’interno dello stack relativo
- il PCB ha le info utili al recupero di questi dati
CPU → trova l’ISR
- accede all’ interrupt vector (una tabella che contiene gli indirizzi delle ISR corrispondenti ai vari tipi di interrupt)
- ISR = codice in C che viene eseguito per gestire un interrupt
- aggiorna il Program Counter (PC) per puntare all'inizio della Interrupt Service Routine (ISR) corrispondente
esecuzione procedura assembly → salva Stato della CPU e prepara un nuovo stack
- registri
- new stack: per eseguire il codice che gestirà l'interrupt, per garantire che la routine di gestione dell'interrupt non sovrascriva lo stack del processo corrente
CPU → esegue l’ISR
- la CPU esegue l’ISR
- nel caso del clock, l’ISR segnala al sistema operativo che il time slice del processo corrente è terminato e attiva lo scheduler
scheduler → decide il prossimo processo da eseguire
in base a:
- priorità
- stato esecutivo
- altre info nel PCB
esecuzione procedura in assembly (dentro il dispatcher) → prepara prossimo processo
- copia i valori salvati nei registri del processo scelto dallo scheduler e il program counter) per eseguirlo da dove era stato interrotto
NOTA
separazione delle Responsabilità:
- Routine in C: per gestire logiche di alto livello, come l'input/output o la gestione di dati → ISR
- Codice Assembly: compiti più vicini all'hardware, come la gestione dei registri e il controllo delle istruzioni di basso livello.
- Il linguaggio assembly è la ragione per cui un sistema operativo non funziona con qualsiasi processore, infatti non è un linguaggio universale ma dipende dall'architettura dei processor.
Sistema multi-thread
si riferisce al funzionamento generale dei thread e a come vengono gestiti in un sistema operativo o in un programma
Un thread rappresenta una singola unità esecutiva di un processo.
- Quando il processo riceve una richiesta, crea un nuovo thread per gestirla. In questo modo, più richieste possono essere soddisfatte contemporaneamente.
- più thread condividono le risorse di un unico processo (memoria, file aperti), ma hanno pure informazioni locali come:
- Program Counter
- Registri
- Stack
- Stato esecutivo
IMPLEMENTAZIONE DEI THREAD (del kernel)
due tipi
- Thread a livello utente: → il sistema operativo vede i processi
- La gestione dei thread avviene a livello di libreria, all'interno del processo. Il sistema operativo non è a conoscenza dei singoli thread, ma gestisce i processi.
- Quando i thread sono implementati in modalità utente…il dispatcher deve essere implementato dal processo
dispatcher (da non confondere con quello della system call)
seleziona il prossimo thread o processo da eseguire: dopo che lo scheduler (il componente che decide l'ordine di esecuzione dei processi) ha scelto quale processo o thread deve essere eseguito, il dispatcher prende in carico il compito di avviare effettivamente quell'esecuzione.
- Thread a livello kernel: → il sistema operativo cede i singoli thread
- Il sistema operativo è a conoscenza dei thread e gestisce lo scheduling anche a livello di thread.
- Esempio: Windows gestisce i thread direttamente, il che rende lo scheduling più complesso ma permette una gestione più efficiente.
- Modello ibrido (M:N): → Il sistema operativo vede sia i processi che un sottoinsieme di thread
- M thread utente sono associati a N thread kernel,
- ho un processo scomposto in M thread utente che sono da eseguire, il processo possiede anche N thread kernel che vanno a mappare i M thread utente da eseguire, quindi il sistema operativo vede i thread kernel e questi scelgono quale thread utente eseguire (quindi il processo sceglie quale thread utente eseguire ma su una porzione più specifica)
Questo modello combina i vantaggi di entrambi gli approcci, ma è complesso da implementare e difficile il debug.
 Made with Bullet
Made with Bullet